
©2025, technoventure, inc.
ϕNames
ϕNames are based on a text encoding system
used extensively in ϕPPL, ϕAsm and ϕOS. They serve as
identifiers, labels and file names. ASCII and Unicode pose
problems when directly used for names in main stream systems.
The advantage ASCII has over Unicode is that every character
requires only one byte of storage. This is memory efficient so
more text can be stored in a given space. However, ASCII is
very limited in its symbol set. And only about one quarter of
these codes are legal for identifier and file names. One of my
biggest turn-offs to UNIX in the early days was its tendency
to accept non-displayable characters (such as control codes
and even those with codes where the high bit is set) for
making file names. I once had a terrible time trying to delete
a file when its apparent name in a listing wouldn't match the
name I supplied when trying to delete the file in a command
line.
Unicode dramatically increases the number of symbols you can use for this purpose. But it suffers from another set of problems. Some of these are shared with ASCII. Code Points have different sizes so you can't place them into arrays unless you make an array of references to them. Alternately, you can turn them into Flat Characters, but this requires minimally three bytes per character. Since most programmers want to use elements that can be naturally aligned in memory, they will just use 32-bit characters which is UTF-32. These things not only entail extra work but they waste memory. The problem with using ASCII or Unicode directly becomes apparent when you need to alphabetize the names. The letter 'a' follows the 'Z' and this shouldn't be. Every character has to be examined to determine if it is eligible as an alphabetic. An algorithm used to figure out where it belongs in a list is not trivial. The problem is aggravated with Unicode because you now have multiple alphabets that can all be thrown in together. Another problem arises when you allow file names with mixed alphabets. Hebrew reads from right to left while Roman reads left to right. You get really screwy behavior when you intermix these alphabets.
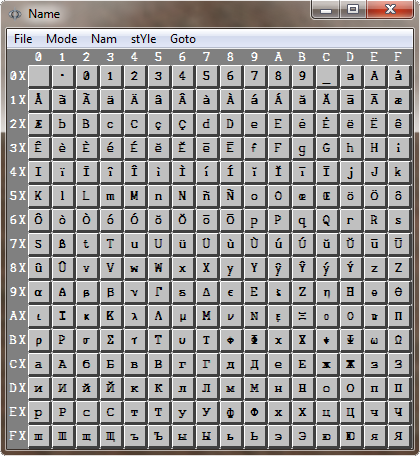
ϕName Identifier Codes (ϕNIC)
ϕNIC encoding solves virtually all of these
problems. In the similar way that C and ϕPPL syntax is
English-based, ϕNames are European character-based. A well
defined subset of Unicode characters are taken from the full
alphabets of Roman, Greek and Cyrillic. All symbols are in the
Multi-lingual Plane so their flat character codes can all fit
into 16 bits. Alphabetic order puts lower case before upper
case. Each of these symbols is assigned an 8-bit code. A
number of commonly used special consonants and vowels with
diacritical marks extend the list of Roman-based characters.
To these are added the ten numerals and the underscore which
is regarded as the first alphabetic character. An additional
character is added as a name separator ($01) and the first one
serves as a zero terminator ($00). This brings the total to
256. All byte codes are defined so there is no way for an
errant control code (or any other displayable for that matter)
to accidentally be inserted into a ϕName. The number of
symbols that can be used is still limited. But the set is four
times what it would be in ASCII. And they can be placed into
arrays because they are all the same size. Having a limited
symbol set keeps the code maintainable when you want an
off-the-self programmer to be able to understand the code. The
alphabetic order of the characters is the same as their
numerical order making sorting a trivial process. Testing for
a character to be alphabetic is easy. It is all of the codes
that are greater than or equal to that of the underscore.
Decoding a ϕNIC is much simpler. A direct array lookup converts them back to Unicode Flat Characters. Their raw values are the same as ϕText Flat Characters stored in 32-bit integers with all property bits cleared. For every time that an ϕNIC character is encoded, it is typically used many times in search and sorting processes. So in the long run, the extra front-end effort is well justified. With the characters only occupying one byte each, processing them in arrays is easy and you save a lot of memory.
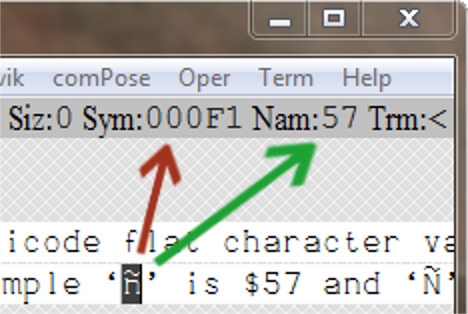
ϕNIC Symbol and ϕName String Literals
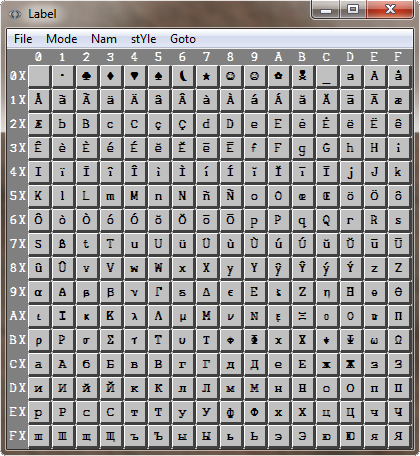
These conventions are patterned after C in which single ASCII symbols are enclosed within single quotes. For example '*'. Zero-terminated strings are enclosed within double quotes. For example "Hello World!". In ϕPPL and ϕAsm, symbols enclosed within single quotes are extended to UTF-32 single characters and strings within double quotes are extended to zero-terminated UTF-8 encoded text. This same pattern is also used in ϕText where single flat characters (type ch) are enclosed within left and right single quotes (such as ‘ϕ’) and zero-terminated strings are enclosed within left and right double quotes (such as “Ye Olde Merry Pub”). Text properties (Color, Attributes, Size and Style) are retained in ϕText while they are lost in UTF-32 and UTF-8, ϕNames and ϕLabels.